ADSP-21160NCBZ-100(RevD) View Datasheet(PDF) - Analog Devices
Part Name
Description
Manufacturer
ADSP-21160NCBZ-100 Datasheet PDF : 58 Pages
| |||
CLOCK
4
3
4
LINK
DEVICES
(6 MAX)
(OPTIONAL)
SERIAL
DEVICE
(OPTIONAL)
SERIAL
DEVICE
(OPTIONAL)
ADSP-21160X
CLKIN
BMS
CLK_CFG3–0 CIF
EBOOT
LBOOT
BRST
IRQ2–0
ADDR31–0
FLAG3–0
TIMEXP DATA63–0
LXCLK
LXACK
LXDAT7–0
RDx
WRx
ACK
MS3–0
TCLK0
RCLK0
TFS0
RSF0
DT0
DR0
PAGE
SBTS
CLKOUT
DMAR1–2
TCLK1
RCLK1
TFS1
RSF1
DT1
DR1
DMAG1–2
CS
HBR
HBG
REDY
RPBA
BR1–6
ID2–0
PA
RESET JTAG
6
CS
BOOT
ADDR EPROM
(OPTIONAL)
DATA
ADDR
DATA MEMORY/
OE MAPPED
WE
DEVICES
(OPTIONAL)
ACK
CS
DMA DEVICE
(OPTIONAL)
DATA
HOST
PROCESSOR
INTERFACE
(OPTIONAL)
ADDR
DATA
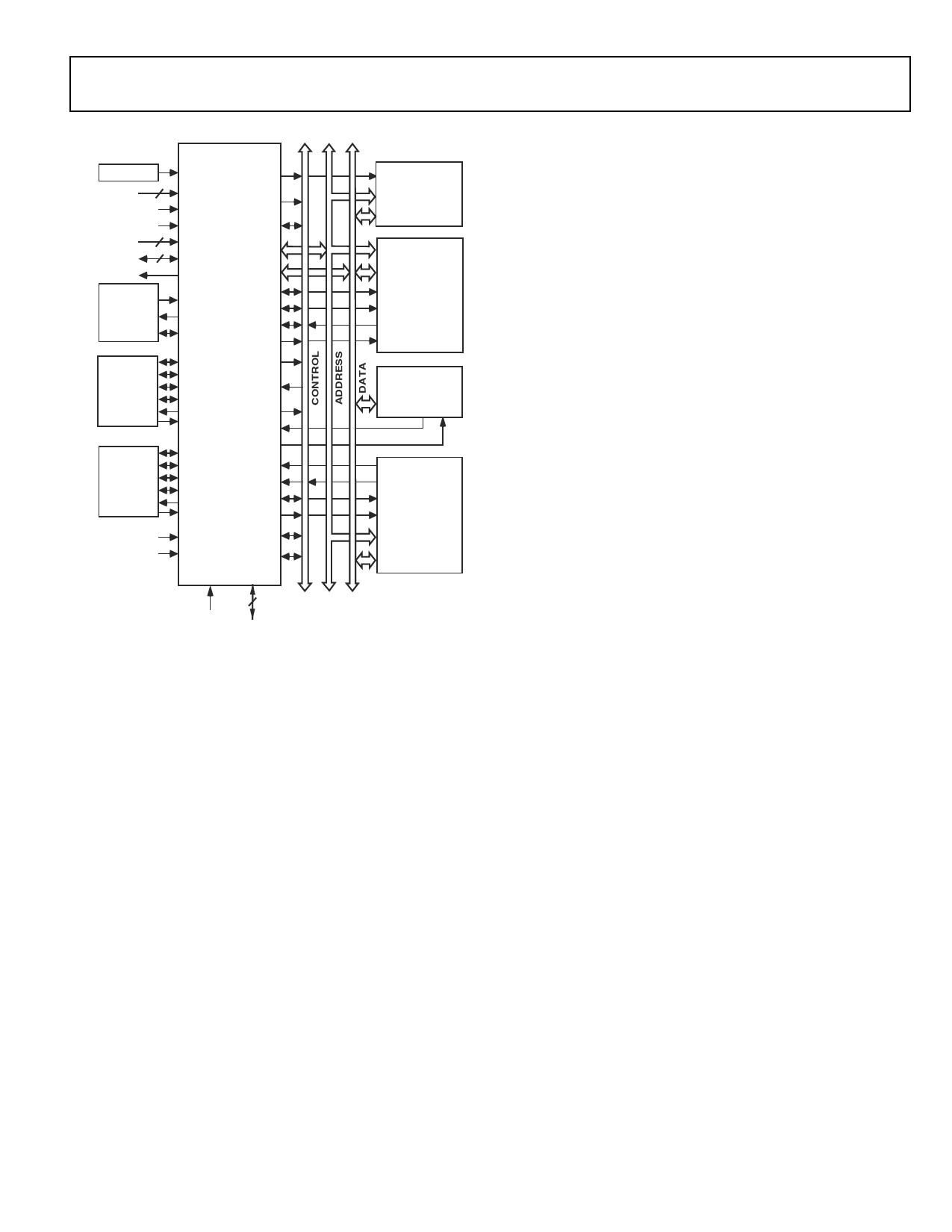
Figure 2. Single-Processor System
enabled, the same instruction is executed in both processing ele-
ments, but each processing element operates on different data.
This architecture is efficient at executing math-intensive DSP
algorithms.
Entering SIMD mode also has an effect on the way data is trans-
ferred between memory and the processing elements. In SIMD
mode, twice the data bandwidth is required to sustain computa-
tional operation in the processing elements. Because of this
requirement, entering SIMD mode also doubles the bandwidth
between memory and the processing elements. When using the
DAGs to transfer data in SIMD mode, two data values are trans-
ferred with each access of memory or the register file.
Independent, Parallel Computation Units
Within each processing element is a set of computational units.
The computational units consist of an arithmetic/logic unit
(ALU), multiplier, and shifter. These units perform single-cycle
instructions. The three units within each processing element are
arranged in parallel, maximizing computational throughput.
Single multifunction instructions execute parallel ALU and
multiplier operations. In SIMD mode, the parallel ALU and
multiplier operations occur in both processing elements. These
computation units support IEEE 32-bit single-precision float-
ing-point, 40-bit extended-precision floating-point, and 32-bit
fixed-point data formats.
ADSP-21160M/ADSP-21160N
Data Register File
A general-purpose data register file is contained in each pro-
cessing element. The register files transfer data between the
computation units and the data buses, and store intermediate
results. These 10-port, 32-register (16 primary, 16 secondary)
register files, combined with the ADSP-2116x enhanced
Harvard architecture, allow unconstrained data flow between
computation units and internal memory. The registers in PEX
are referred to as R0–R15 and in PEY as S0–S15.
Single-Cycle Fetch of Instruction and Four Operands
The processor features an enhanced Harvard architecture in
which the data memory (DM) bus transfers data, and the pro-
gram memory (PM) bus transfers both instructions and data
(see the functional block diagram 1). With the ADSP-21160x
DSP’s separate program and data memory buses and on-chip
instruction cache, the processor can simultaneously fetch four
operands and an instruction (from the cache), all in a single
cycle.
Instruction Cache
The ADSP-21160x includes an on-chip instruction cache that
enables three-bus operation for fetching an instruction and four
data values. The cache is selective—only the instructions whose
fetches conflict with PM bus data accesses are cached. This
cache allows full-speed execution of core, providing looped
operations, such as digital filter multiply- accumulates and FFT
butterfly processing.
Data Address Generators with Hardware Circular Buffers
The ADSP-21160x DSP’s two data address generators (DAGs)
are used for indirect addressing and provide for implementing
circular data buffers in hardware. Circular buffers allow efficient
programming of delay lines and other data structures required
in digital signal processing, and are commonly used in digital
filters and Fourier transforms. The two DAGs of the product
contain sufficient registers to allow the creation of up to 32 cir-
cular buffers (16 primary register sets, 16 secondary). The DAGs
automatically handle address pointer wraparound, reducing
overhead, increasing performance, and simplifying implemen-
tation. Circular buffers can start and end at any memory
location.
Flexible Instruction Set
The 48-bit instruction word accommodates a variety of parallel
operations for concise programming. For example, the proces-
sor can conditionally execute a multiply, an add, and subtract,
in both processing elements, while branching, all in a single
instruction.
Rev. D | Page 5 of 58 | September 2015
Share Link: 